
# kubelet
## 架构

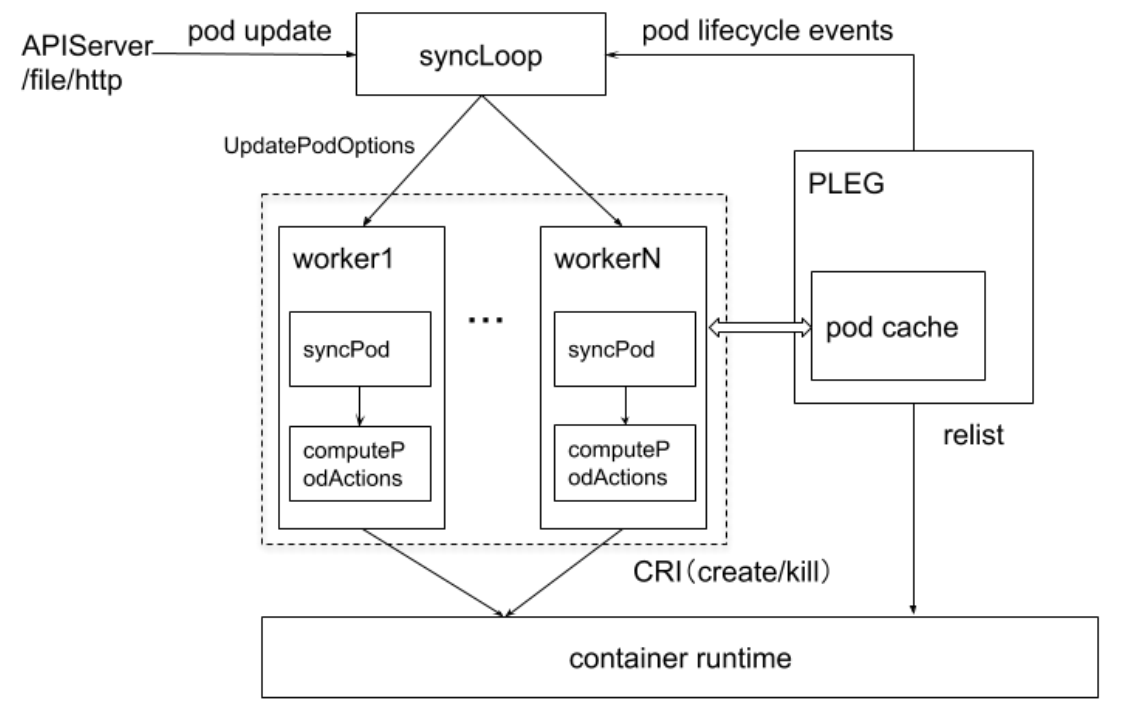
## Kubelet管理Pod核心流程
Kubelet 进程会限制最大 Pod数,因为 Kubelet会每秒 gRPC调用 CRI查询 Pod信息(PLEG部分),并上报到 Kube-ApiServer。
如果 Pod数量很多,可能会导致 CRI接口超时或崩溃。
## Pod启动流程
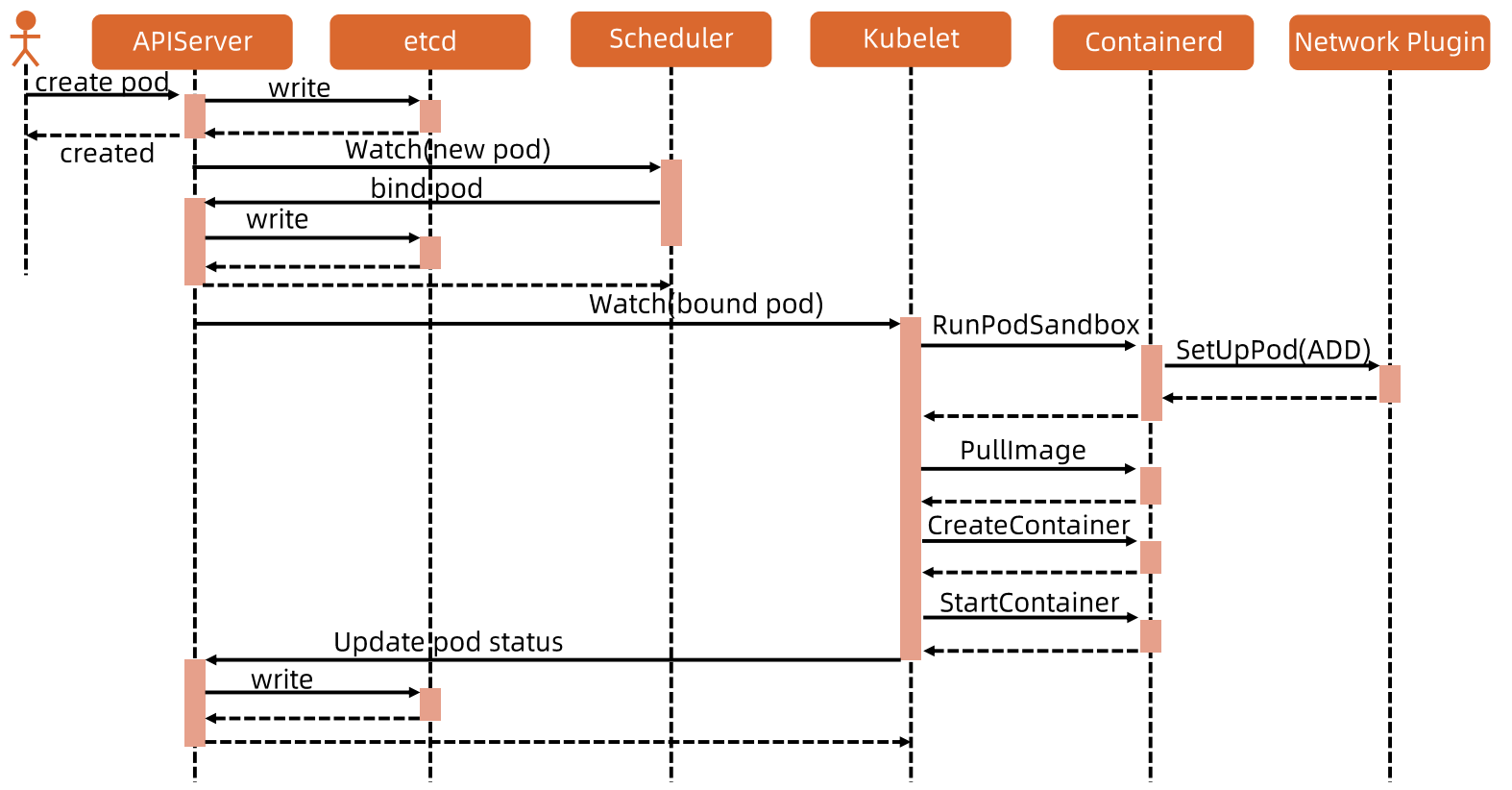
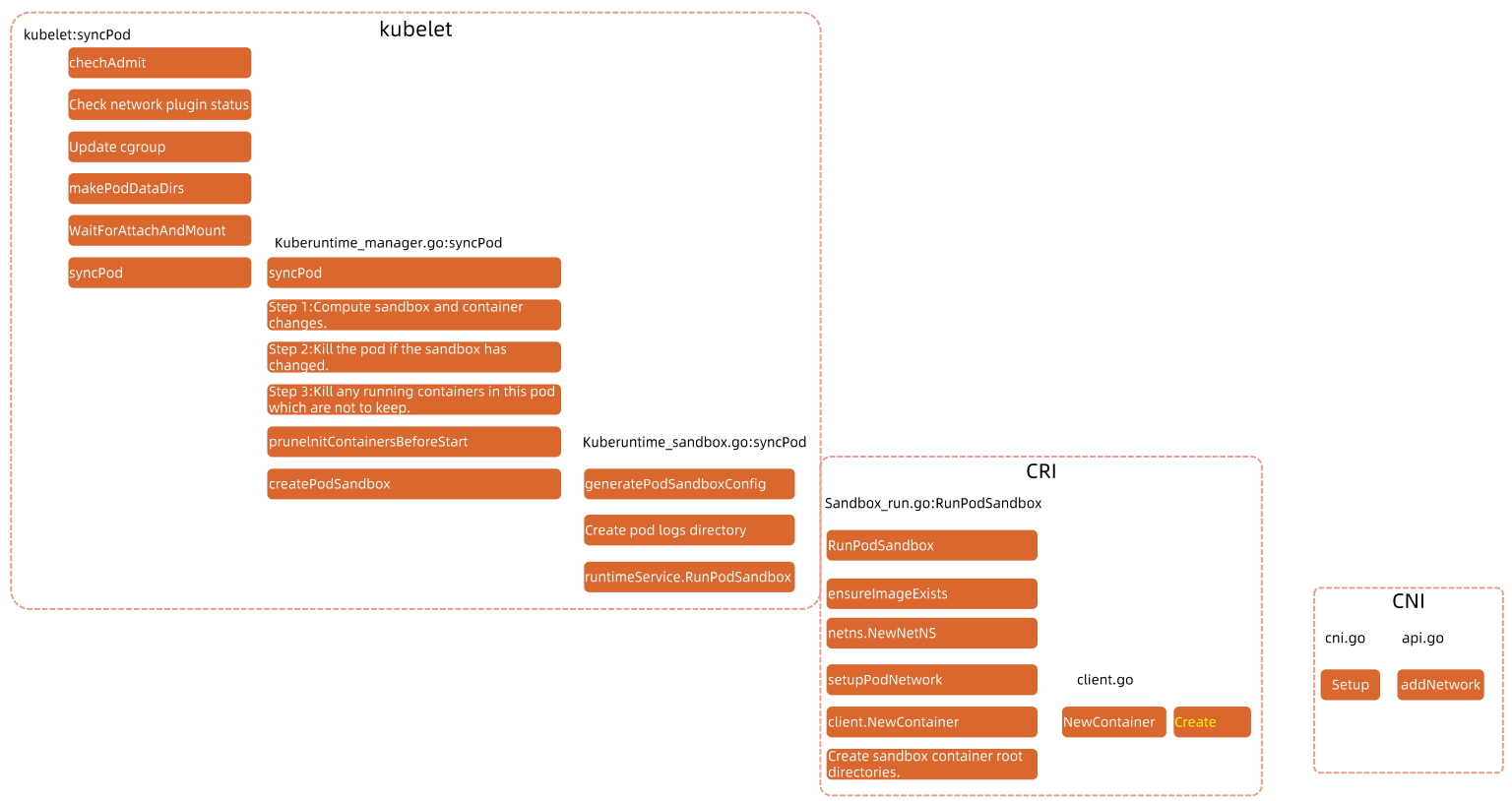
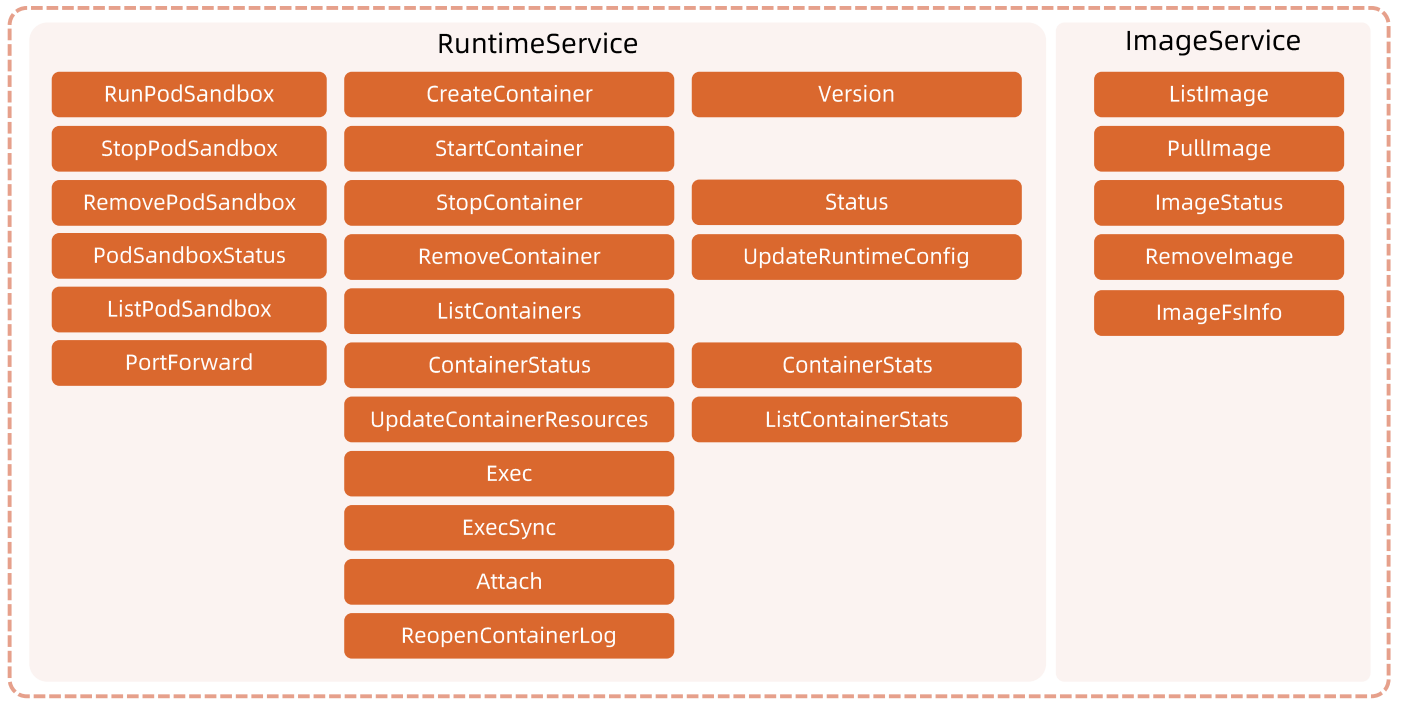
CRI 大体包含三部分接口:Sandbox 、 Container 和 Image。
https://github.com/kubernetes/cri-api/blob/c75ef5b/pkg/apis/runtime/v1/api.proto
Sandbox 是Pod 创建时最先启动的 Container,为 Container 提供一定的运行环境,这其中包括 pod 的网络等。
PodSandbox 其实就是 pause 容器。
# CRI
## 介绍
CRI 是 Kubernetes定义的一组 gRPC服务。Kubelet 作为客户端,基于 gRPC框架,通过 **Socket** 和容器运行时通信。
它包括两类服务:镜像服务(Image Service)和运行时服务(Runtime Service)。
**镜像服务**:提供下载、检查和删除镜像的远程程序调用。
**运行时服务**:包含用于管理容器生命周期,以及与容器交互的调用(exec/attach/port-forward)的远程程序调用。
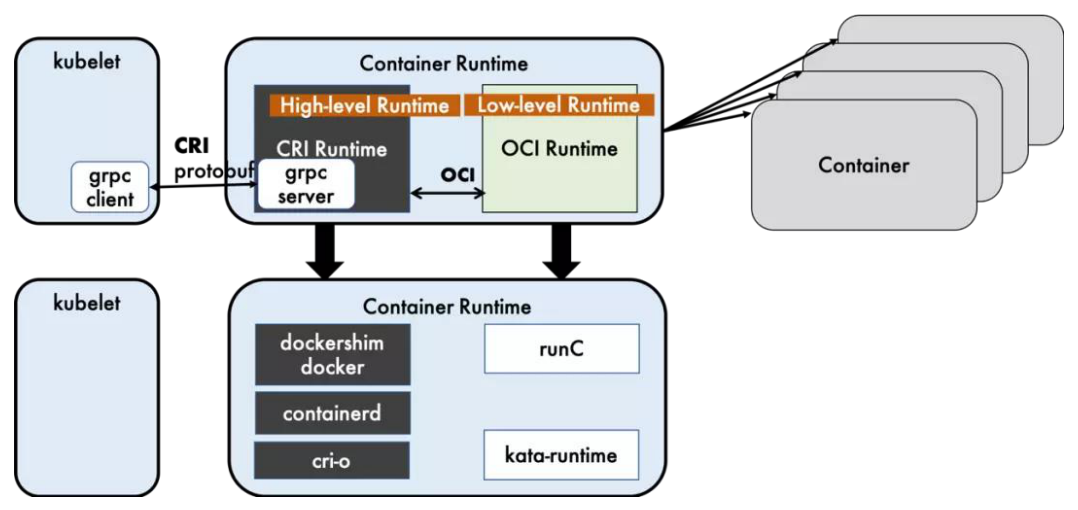
## 运行时的层级
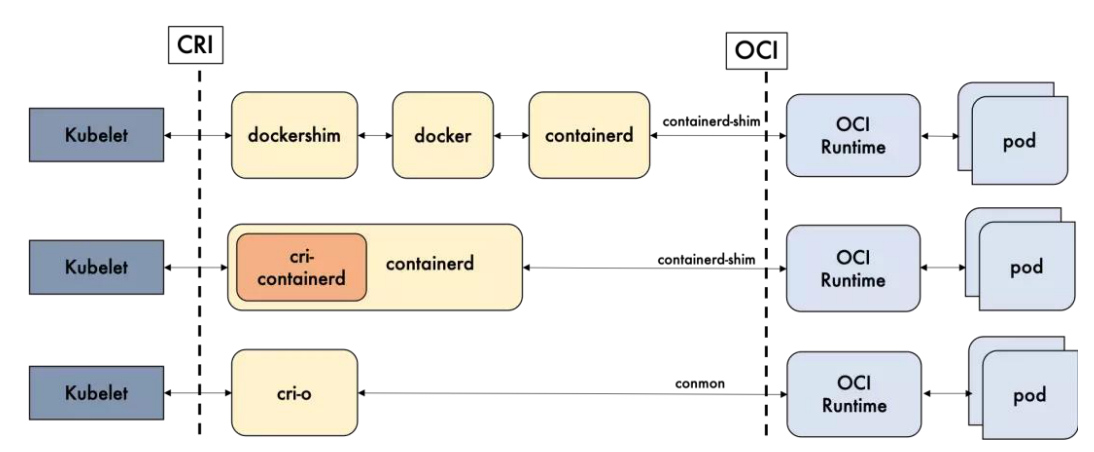
Docker-shim、Containerd 和 CRI-O都是遵循 CRI的容器运行时,称为**高层级运行时**。
OCI(Open Container Initiative,开放容器计划)定义了创建容器的格式和运行时的开源行业标准,包括 镜像规范 和 运行时规范。
镜像规范定义了 OCI镜像的标准。高层级运行时将会下载一个 OCI镜像,并把它解压成 OCI运行时文件系统包。
运行时规范则描述了如何从 OCI运行时文件系统包运行容器程序。如何为新容器设置 Namespace 和 Cgroup。它的一个参考实现是 runC。称为**低层级运行时**
## CRI实现功能
## 开源运行时的比较
# CNI
## 介绍
在Kubernetes中,提供了一个轻量的通用容器网络接口CNI,专门用于设置和删除容器的网络联通性。
容器运行时通过 CNI调用网络插件来完成容器的网络设置。
Kubelet 来查找 CNI插件的,运行插件来为容器设置网络,这两个参数应该配置在Kubelet处:
`cni-cin-dir: 网络插件的可执行文件所在目录,默认是/opt/cni/bin`
`cni-conf-dir: 网络插件的配置文件所在目录,默认是/etc/cni/net.d`
## Calico 网络模式
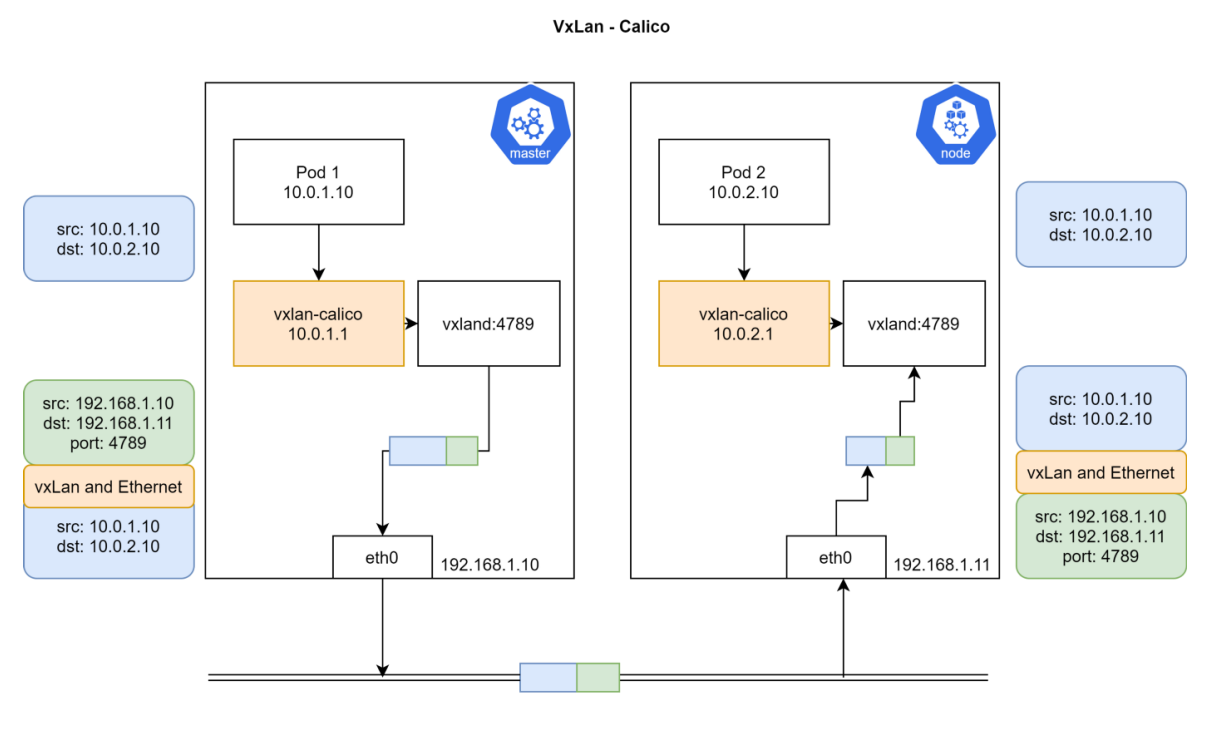
VXLAN 模式是通过 UDP协议进行封包,需要 CNI插件在用户态封包、解包,效率比较低。
**VXLAN模式**
数据包首先会通过 `veth pair` 达到 Node节点,然后都会经过 4789端口对应的进程,进行封包、解包。
**IPIP模式**
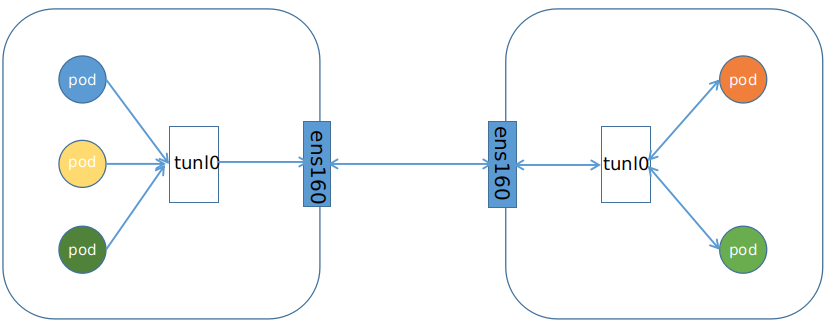
从字面上理解,就是把一个IP数据包又套在一个IP包里,即把IP层封装到IP层的一个Tunnel。它的作用其实基本上就相当于一个基于IP层的网桥。一般来说,普通的网桥是基于MAC层的,不需要IP,而这个IP则是通过两端的路由做一个Tunnel,把两个本来不通的网络通过点对点连接起来。
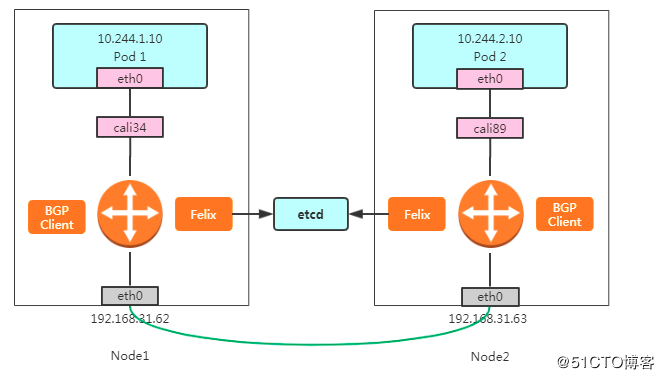
**BGP模式**
Calico 项目实际上将集群里的所有节点,都当作是边界路由器来处理,它们一起组成了一个全连通的网络,互相之间通过 BGP 协议交换路由规则
这里最核心的 下一跳 路由规则,就是由 Calico 的 Felix 进程负责维护的。这些路由规则信息,则是通过 BGP Client 中 BIRD 组件,使用 BGP 协议来传输。
# kube-scheduler
## 介绍
kube-scheduler 负责分配调度 Pod 到集群内的节点上,它监听 kube-apiserver,查询还未分配 Node 的 Pod,然后根据调度策略为这些 Pod 分配节点(更新 Pod 的 NodeName 字段)。
## 策略
**kube-scheduler 分为两个阶段,predicate(预选)和 priority(优选)。**
**每个阶段中会有很多策略,策略是以插件的形式集成在 kube-scheduler,也可以自己编写策略。**
### predicate(预选)

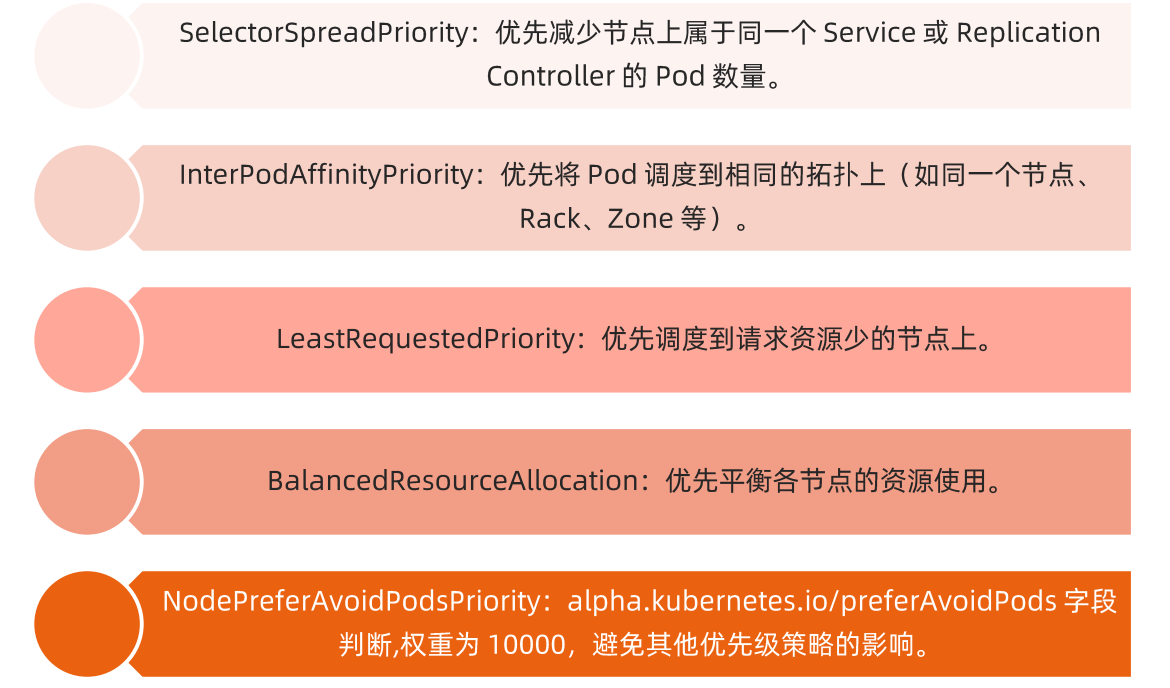
### priority(优选)
### QoS(服务质量)
Kubernetes 创建 Pod 时就给它指定了下列一种 QoS 类:`Guaranteed`,`Burstable`,`BestEffort`。
- Guaranteed:Pod 中的每个容器,包含初始化容器,必须指定内存和 CPU 的requests和limits,并且两者要相等。
- Burstable:Pod 不符合 Guaranteed QoS 类的标准;Pod 中至少一个容器具有内存或 CPU requests。
- BestEffort:Pod 中的容器必须没有设置内存和 CPU requests或limits。
**Qos Class优先级排名:Guaranteed > Burstable > Best-Effort**
当节点资源紧缺时,优先级低的pod会最先被节点驱逐
### 代码示例
```golang
// Framework manages the set of plugins in use by the scheduling framework.
// Configured plugins are called at specified points in a scheduling context.
type Framework interface {
Handle
QueueSortFunc() LessFunc
RunPreFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod) *Status
RunPostFilterPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, filteredNodeStatusMap NodeToStatusMap) (*PostFilterResult, *Status)
RunPreBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunPostBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunReservePluginsReserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
RunReservePluginsUnreserve(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string)
RunPermitPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
WaitOnPermit(ctx context.Context, pod *v1.Pod) *Status
RunBindPlugins(ctx context.Context, state *CycleState, pod *v1.Pod, nodeName string) *Status
HasFilterPlugins() bool
HasPostFilterPlugins() bool
HasScorePlugins() bool
ListPlugins() *config.Plugins
ProfileName() string
}
Schedule()-->
// filter
g.findNodesThatFitPod(ctx, extenders, fwk, state, pod)-->
// 1.filter预处理阶段:遍历pod的所有initcontainer和主container,计算pod的总资源需求
s := fwk.RunPreFilterPlugins(ctx, state, pod) // e.g. computePodResourceRequest
// 2. filter阶段,遍历所有节点,过滤掉不符合资源需求的节点
g.findNodesThatPassFilters(ctx, fwk, state, pod, diagnosis, allNodes)-->
fwk.RunFilterPluginsWithNominatedPods(ctx, state, pod, nodeInfo)-->
s, err := getPreFilterState(cycleState)
insufficientResources := fitsRequest(s, nodeInfo, f.ignoredResources, f.ignoredResourceGroups)
// 3. 处理扩展plugin
findNodesThatPassExtenders(extenders, pod, feasibleNodes, diagnosis.NodeToStatusMap)
// score
prioritizeNodes(ctx, extenders, fwk, state, pod, feasibleNodes)-->
// 4. score,比如处理弱亲和性,将preferredAffinity语法进行解析
fwk.RunPreScorePlugins(ctx, state, pod, nodes) // e.g. nodeAffinity
fwk.RunScorePlugins(ctx, state, pod, nodes)-->
// 5. 为节点打分
f.runScorePlugin(ctx, pl, state, pod, nodeName) // e.g. noderesource fit
// 6. 处理扩展plugin
extenders[extIndex].Prioritize(pod, nodes)
// 7.选择节点
g.selectHost(priorityList)
sched.assume(assumedPod, scheduleResult.SuggestedHost)-->
// 8.假定选中pod
sched.SchedulerCache.AssumePod(assumed)-->
fwk.RunReservePluginsReserve(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)-->
f.runReservePluginReserve(ctx, pl, state, pod, nodeName) // e.g. bindVolume。其实还没大用
runPermitStatus := fwk.RunPermitPlugins(schedulingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost)-->
f.runPermitPlugin(ctx, pl, state, pod, nodeName) // empty hook
fwk.RunPreBindPlugins(bindingCycleCtx, state, assumedPod, scheduleResult.SuggestedHost) // 同 runReservePluginReserve
// bind
// 9.绑定pod
sched.bind(bindingCycleCtx, fwk, assumedPod, scheduleResult.SuggestedHost, state)-->
f.runBindPlugin(ctx, bp, state, pod, nodeName)-->
b.handle.ClientSet().CoreV1().Pods(binding.Namespace).Bind(ctx, binding, metav1.CreateOptions{})-->
return c.client.Post().Namespace(c.ns).Resource("pods").Name(binding.Name).VersionedParams(&opts, scheme.ParameterCodec).SubResource("binding").Body(binding).Do(ctx).Error()
```

云原生训练营:Kubernetes控制平面组件
Copyright: 采用 知识共享署名4.0 国际许可协议进行许可
Links: https://blog.zs-fighting.cn/archives/云原生训练营kubernetes控制平面组件

