
# 稀疏特征和密集特征
稀疏特征和密集特征是机器学习和深度学习中常见的两种特征类型,它们有不同的存储方式和处理方法。
在机器学习中,特征是指对象、人或现象的可测量和可量化的属性或特征。特征可以大致分为两类:稀疏特征和密集特征。
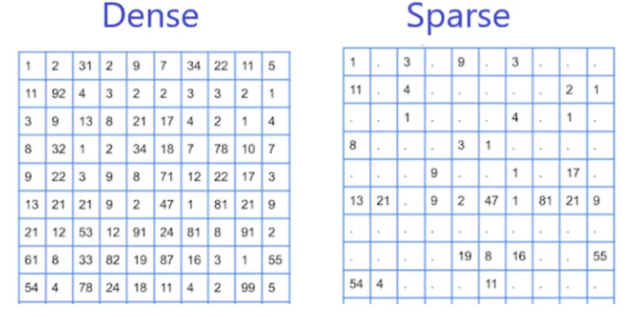
**稀疏特征(Sparse Feature)** 指的是特征值大部分为0的特征,例如文本数据中的词频、one-hot向量等。对于稀疏特征,我们通常使用稀疏矩阵(Sparse Matrix)来存储,只存储非0的元素和它们的索引,可以大大节省存储空间和计算资源。在深度学习中,我们也可以使用Embedding层来对稀疏特征进行编码,将高维稀疏向量映射为低维稠密向量,以便进行神经网络的训练和推理。
**密集特征(Dense Feature)** 指的是特征值大部分为非0的特征,例如图像数据中的像素值、音频数据中的频谱、时间序列数据中的数值等。对于密集特征,我们通常使用密集矩阵(Dense Matrix)来存储,每个元素都有一个实数值。在深度学习中,我们通常使用全连接层(Dense层)来对密集特征进行编码,将输入特征向量映射为输出特征向量,以便进行神经网络的训练和推理。
**区别**
稀疏特征和密集特征之间的区别在于它们的值在数据集中的分布。稀疏特征具有很少的非零值,而密集特征具有许多非零值,这种分布差异对机器学习算法有影响,因为与密集特征相比,算法在稀疏特征上的表现可能不同。
需要注意的是,稀疏特征和密集特征并不是互相独立的,实际的数据集通常包含多种类型的特征,其中一些特征可能是稀疏的,一些特征可能是密集的,甚至还可能包含序列、图像、音频等多种类型的数据。在处理这些数据时,我们需要根据不同的特征类型选择合适的存储方式和处理方法,以便提高模型的效率和准确率。
**算法选择**
现在我们知道了给定数据集的特征类型,如果数据集包含稀疏特征或数据集包含密集特征,我们应该使用哪种算法?
一些算法更适合稀疏数据,而另一些算法更适合密集数据。
- 对于稀疏数据,流行的算法包括逻辑回归、支持向量机 (SVM) 和决策树。
- 对于密集数据,流行的算法包括神经网络,例如前馈网络和卷积神经网络。
但需要注意的是,算法的选择不仅仅取决于数据的稀疏性或密度,还应考虑数据集的大小、特征类型、问题的复杂性等其他因素 ,一定要尝试不同的算法并比较它们在给定问题上的性能。
# NN[神经网络]中embedding的dense和sparse是什么意思?
dense 表示稠密,在embedding中的dense时:
假设我们有这样一个句子: “北京是北京”,我们将其数值化表示为:
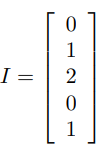
dense embedding,需要你讲它转换成onehot表示:
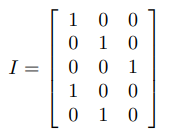
假设embedding对输出size=3,也就是hidden层的size=3*3;
eg:
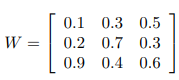
那么dense layer的计算过程就是一个矩阵相乘:

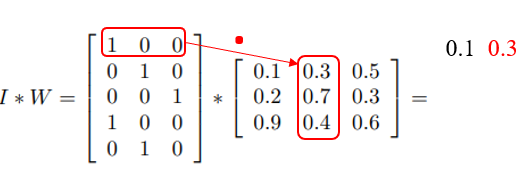


整个流程展开来看就是:
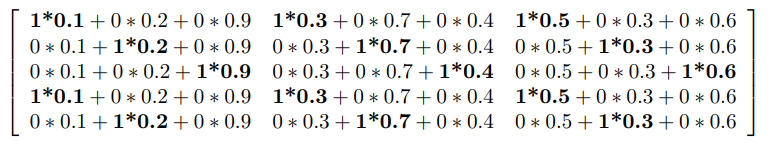
你会看到这个过程:
1. 计算量非常巨大 ,这个回想一下矩阵乘法的复杂度就知道O((N*M)*(M*M)),
2. 而且对于输入来说,转换的矩阵也很巨大(就是vocabulary有多大,这个列就有多大,你想想当vocabulary=500w时,这个输入input的表示矩阵大不大).
那么有没有方法,优化一下这两个问题(计算量大,输入尺寸也大)呢?
sparse : 表示稀疏,在embedding中的dense时:
同样假设我们有这样一个句子: “北京是北京”,我们将其数值化表示为:
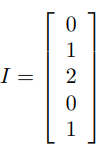
sparse embedding,不需要你转换乘onehot编码格式:
那么,它是如何计算的呢?
假设embedding对输出size=3,也就是hidden层的size=3*3;
eg:
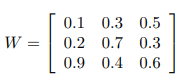
那么sparse layer的计算过程的“矩阵相乘”(相当于一个查表的过程,所以有lookup_table这个表述):
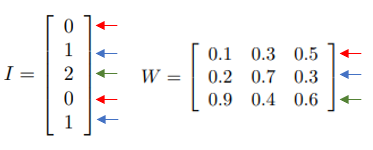
这个计算过程为:

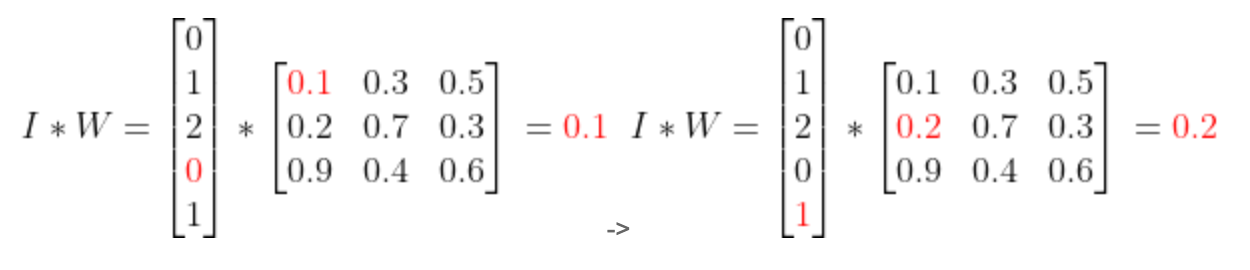
最终得到:

你会看到,dense和sparse结果都一样,但是这个计算量变成列O((N*1)*(M*M)) 减少列一个量级. 而且输入input的vec也极大的缩小了,毕竟存储的是index嘛.
那么会到我们开始的问题,NN[神经网络]中embedding的dense和sparse是什么意思?
结合上面的例子的计算过程,dense embedding 就是要求输入必须为onehot,sparse embedding 不需要.
那么在扩大一点,NN[神经网络]中的dense和sparse是什么意思?
dense和sparse描述的是该层hidden layer和前后层的网络连接情况,如果hidden layer 和前一层以及后一层参数连接多,我们就说他是dense layer,比如全连接层(fc),相反,如果连接数比较少,我们说它是sparse layer。

稀疏特征和密集特征
Copyright: 采用 知识共享署名4.0 国际许可协议进行许可
Links: https://blog.zs-fighting.cn/archives/xi-shu-te-zheng-he-mi-ji-te-zheng-

