
# Flannel
## 工作模式
Flannel支持多种工作模式:
- UDP:使用设备 flannel.0 进行封包解包,不是内核原生支持,频繁地内核态用户态切换,性能非常差。
- VXLAN:使用 flannel.1 进行封包解包,内核原生支持,性能较强。
- Host-GW:Flannel通过在各个节点上的Agent进程,将容器网络的路由信息写到主机的路由表上,这样一来所有的主机都有整个容器网络的路由数据了。
## VXLAN模式
通过在UDP数据包中封装第2层以太网帧帮助实现大型云部署。VXLAN是一种overlay网络,可在现有网络之上运行。
VxLAN,即Virtual Extensible LAN(虚拟可扩展局域网),是Linux本身支持的一网种网络虚拟化技术。VxLAN可以完全在内核态实现封装和解封装工作,从而通过“隧道”机制,构建出 Overlay 网络(Overlay Network)。
**各个组件解释**
`Cni0` :网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡)。Pod从网卡eth0发出的流量都会发送到Cni0网桥设备的端口(网卡)上。
`Flannel.1`: overlay网络的设备,用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端。
`Flanneld`:flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac,ip等网络数据信息。

cni0是一个Linux网桥,flannel.1是一个Linux虚拟网络设备,类型为VXLAN,容器与cni0之间通过veth-pair连接。
假设容器A(172.26.0.2)向容器B(172.26.1.2)发送ping(对应上图的inner IP Header)。
1、首先数据包根据容器A的路由到达cni0网桥,然后根据下面的路由,数据包最终会从flannel.1网卡出去
```shell
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
172.26.0.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
172.26.1.0 172.26.1.0 255.255.255.0 UG 0 0 0 flannel.1
```
2、当数据包到达flannel.1时,对其进行封装。下一跳地址为172.26.1.0/32,于是就会查找flannel.1的ARP表(这个ARP表由flanneld进行维护),如下:
```shell
$ ip neigh show dev flannel.1
172.26.1.0 lladdr 92:8d:c4:85:16:ad PERMANENT
```
查到对应ARP条目后,对数据包进行二层封装(对应上图的inner Ethernet Header)。然后对数据帧封装一层VXLAN Header,这个头部中会包含VNI(所有节点flannel的VNI都为1,这也是叫flannel.1的原因)。
3、VXLAN模块会进行UDP封装,需要知道:源IP、源端口、目的IP、目的端口。
首先目的端口都是8472,内核中默认为VXLAN分配的UDP端口。
源端口是随机端口。接下来是目的IP,Linux下的VXLAN设备都有一个转发表(由flanneld进程维护),如下:
```shell
$ bridge fdb show dev flannel.1 | grep 92:8d:c4:85:16:ad
92:8d:c4:85:16:ad dev flannel.1 dst 192.168.2.103 self permanent
```
目的IP在上面可以获取到192.168.2.103。
最后是源IP,任何一个VXLAN设备创建时都会指定一个三层物理网络设备作为VTEP,这个物理网络设备的IP就是UDP的源IP。使用以下命令可以查看到,源IP是192.168.2.102
```shell
$ ip -d link show flannel.1
```
4、UDP的四元组确定后,VXLAN调用UDP协议的发包函数进行发包。
当数据包到达对端主机的8472端口后,VXLAN模块就会比较这个VXLAN Header中的VNI 和 本机的VETP的VNI时候一致(就是flannel.1),然后比较Inner Ethernet Header中的目的MAC地址与本机的flannel.1的是否一致,都一致的话,则去掉数据包的VXLAN Header和Inner Ethernet Header
5、然后把数据包从flannel.1进行发送。在节点上会有如下路由(由flanneld维护),根据路由判断要发送到cni0网卡上。
```shell
$ route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
...
172.26.1.0 0.0.0.0 255.255.255.0 U 0 0 0 cni0
```
# IPVS
## 介绍
IPVS是LVS的负载均衡模块,基于netfilter,但比iptables性能更高,具备更好的扩展性。Kube-proxy的IPVS模式在Kubernetes 1.11版本达到稳定。
iptables难以扩展到支持成千上万的服务,纯粹是为防火墙设计的,并且底层路由表的实现是链表,对路由规则的增删改查都涉及遍历一次链表。如果我们有1000个服务并且每个服务有10个后端pod,将在每个工作节点上至少产生10000*N个iptables规则,这可能使内核非常繁忙地处理每次iptables规则的刷新。
## IPVS模式实现原理

一旦创建service、endpoints,IPVS模式的Kube-proxy会做以下三件事
- 确保一块dummy网卡(kube-ipvs0)存在。为什么要创建dummy网卡?因为IPVS的netfilter钩子挂载INPUT链,我们需要把Service的访问IP绑定在dummy网卡上,让内核“觉得”虚IP就是本机IP,从而进入INPUT链。
- 把Service的访问IP绑定在dummy网卡上。
- 通过socket调用,创建IPVS的virtual server和real server,分别对应Service和Endpoint
例子:
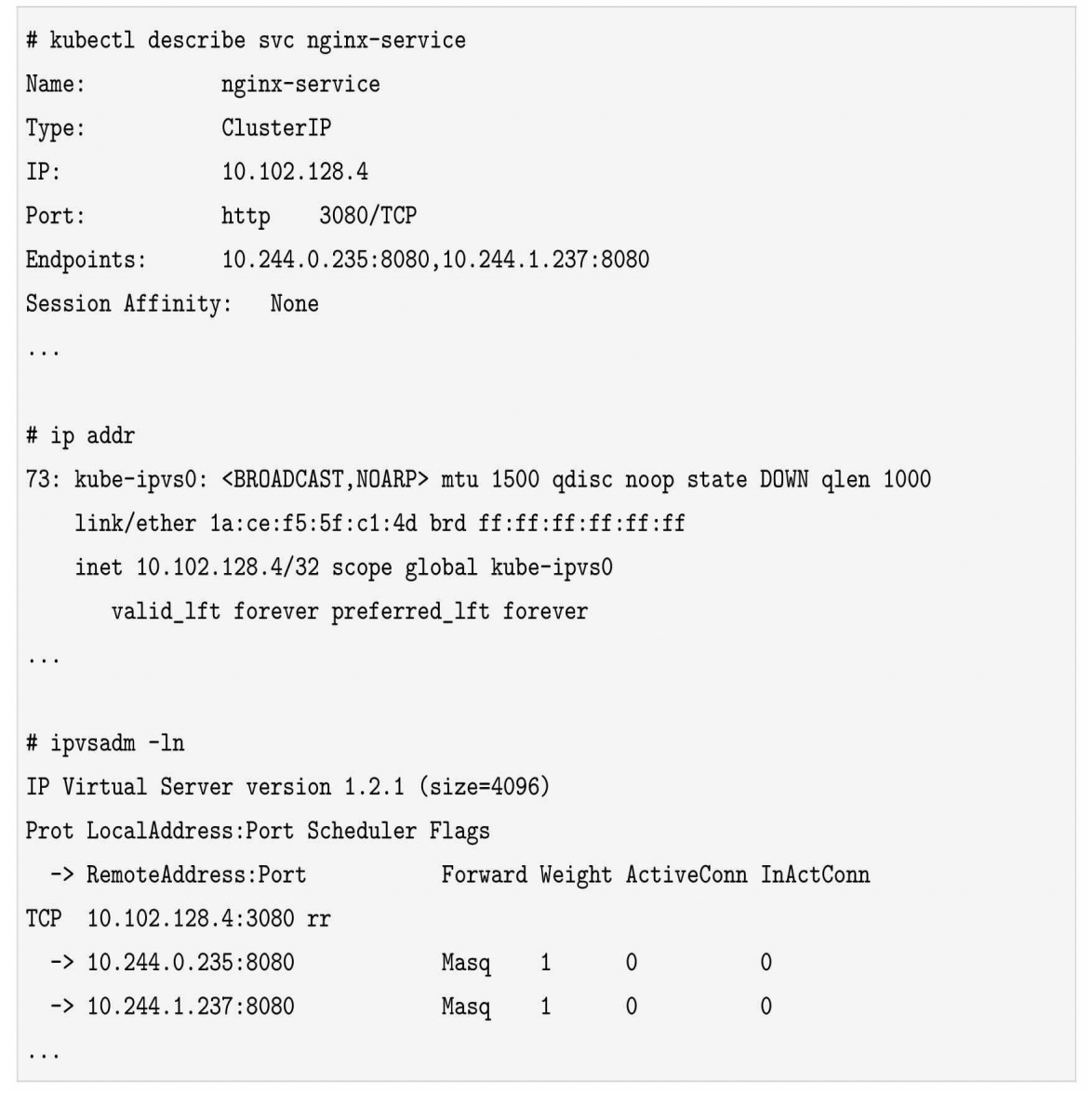
删除Kubernetes的Service将触发删除相应的IPVS virtual server、IPVS real server和绑定在dummy网卡上的IP地址。
IPVS有NAT、ipip、DR三种模式,只有NAT模式支持端口映射。所以Kube-proxy的IPVS使用的NAT模式。
Kube-proxy实现的是分布式负载均衡,而非集中式负载均衡。何谓分布式负载均衡呢?就是每个节点都充当一个负载均衡器,每个节点上都会被配置一摸一样的转发规则。
## iptables 与 ipvs 对比




Kubernetes 网络
Copyright: 采用 知识共享署名4.0 国际许可协议进行许可
Links: https://blog.zs-fighting.cn/archives/kubernetes-flannel

