
# 背景
kafka 消费重平衡机制,就是让一个消费者组下所有的 Consumer 实例就如何消费订阅主题的所有分区达成共识的过程。在重平衡过程中,所有 Consumer 实例共同参与,在协调者组件的帮助下,完成订阅主题分区的分配。但是,在整个过程中,所有实例都不能消费任何消息,会影响到我们业务消息的正常消费。
kafka 重平衡的弊端主要有3个:
1、重平衡会影响Consumer 端 TPS,从而影响整体消费端性能。
2、重平衡过程很慢。如果某个消费者下面的 Group 下成员很多,就会遇到这样的痛点。
3、重平衡效率不高。所有消费成员都要参与,每个消费成员都需要重新抢占分区来进行消费。
所以我们在使用kafka进行消息消费的时候,需要注意尽量避免消费重平衡。
# 原因分析
要避免消费端的重平衡,还是要从 Rebalance 发生的时机入手。
Rebalance 发生的时机有三个:1、消费组成员数量发生变化。2、订阅主题数量发生变化。3、订阅主题的分区数发生变化。
订阅主题数量和订阅主题分区数量变化这两个通常都是运维的主动操作,所以它们引发的 Rebalance 大都是不可避免的。接下来,我们主要说说因为组成员数量变化而引发的重平衡该如何避免。如果 Consumer Group 下的 Consumer 实例数量发生变化,就一定会引发重平衡。这是 Rebalance 发生的最常见的原因。一般来说我们碰到的 99% 的 重平衡,都是这个原因导致的。
Consumer 实例数增加的情况很好理解,当我们启动一个配置有相同 group.id 值的 Consumer 应用程序时,实际上就向这个 Group 添加了一个新的 Consumer 实例成员。此时,kafka的Coordinator 会接纳这个新实例,将其加入到组中,并重新分配分区。通常来说,增加 Consumer 实例的操作都是计划内的,可能是出于增加 TPS 或提高伸缩性的需要。总之,它不属于我们要规避的那类“不必要 Rebalance”。
对于Consumer 实例数减少的情况,需要分2种情况来看:1、开发者自行停掉某些 Consumer 实例,这种属于正常现象。另外一种情况是:Consumer 实例会被 Coordinator 错误地认为“已停止”从而被“踢出”Group。如果是这个原因导致的 重平衡,那么我们就要尽量去进行规避了。
# 解决方案
当我们的消费程序出现间接性消费缓慢或者超时异常的时候,可能是遇到消费者组重平衡了。接下来我们就要聊聊如果规避了。
当 Consumer Group 完成 重平衡之后,每个 Consumer 实例都会定期地向 Coordinator 发送心跳请求,表明它还存活着。如果某个 Consumer 实例不能及时地发送这些心跳请求,Coordinator 就会认为该 Consumer 已经“死”了,从而将其从 Group 中移除,然后开启新一轮重平衡。
Consumer 端有个参数,叫 session.timeout.ms,就是被用来表征此事的。该参数的默认值是 10 秒,即如果 Coordinator 在 10 秒之内没有收到 Group 下某 Consumer 实例的心跳,它就会认为这个 Consumer 实例已经挂了。可以这么说,session.timeout.ms 决定了 Consumer 存活性的时间间隔。除了这个参数,Consumer 还提供了一个允许你控制发送心跳请求频率的参数,就是 heartbeat.interval.ms。这个值设置得越小,Consumer 实例发送心跳请求的频率就越高。频繁地发送心跳请求会额外消耗带宽资源,但好处是能够更加快速地知晓当前是否开启 Rebalance。
### 第一种情况规避方法:
第一类非必要 Rebalance 是因为未能及时发送心跳,导致 Consumer 被“踢出”Group 而引发的。因此,需要仔细地设置 session.timeout.ms 和 heartbeat.interval.ms 的值。在这里给出一些推荐数值:
1、设置 session.timeout.ms = 6s。
2、设置 session.timeout.ms = 6s。
3、要保证 Consumer 实例在被判定为“dead”之前,能够发送至少 3 轮的心跳请求,即 session.timeout.ms >= 3 * heartbeat.interval.ms。
### 第二种情况规避方法:
第二类非必要 Rebalance 是 Consumer 消费时间过长导致的。例如在这样的场景中,Consumer 消费数据时需要将消息处理之后写入到 MongoDB。显然,这是一个很重的消费逻辑。MongoDB 的一丁点不稳定都会导致 Consumer 程序消费时长的增加。此时,max.poll.interval.ms 参数值的设置显得尤为关键。如果要避免非预期的 Rebalance,你最好将该参数值设置得大一点,比你的下游最大处理时间稍长一点。就拿 MongoDB 这个例子来说,如果写 MongoDB 的最长时间是 7 分钟,那么你可以将该参数设置为 8 分钟左右。
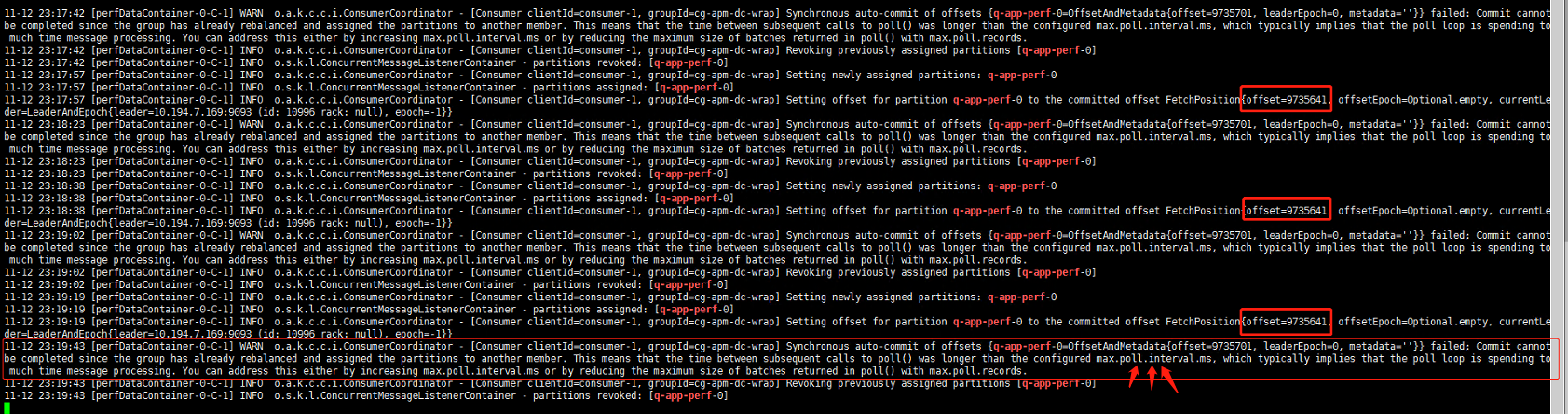

kafka:消费者组反复重平衡问题解决之道
Copyright: 采用 知识共享署名4.0 国际许可协议进行许可

