
# etcd安装
[raft动图演示](http://www.kailing.pub/raft/index.html)
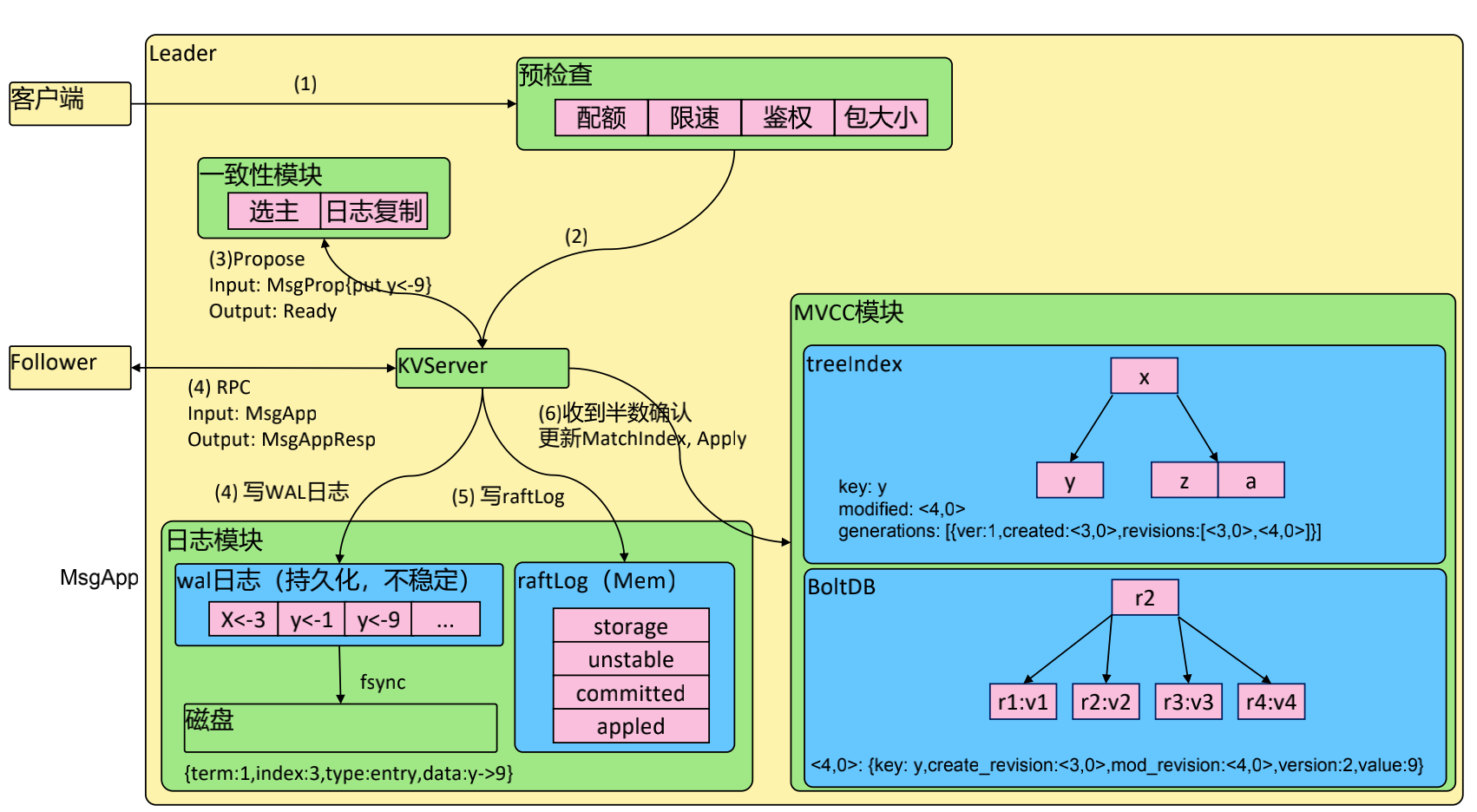
## 存储流程
## 生成证书
```bash
wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
chmod +x cfssl_linux-amd64 cfssljson_linux-amd64 cfssl-certinfo_linux-amd64
cp cfssl_linux-amd64 /usr/local/bin/cfssl
cp cfssljson_linux-amd64 /usr/local/bin/cfssljson
cp cfssl-certinfo_linux-amd64 /usr/bin/cfssl-certinfo
# 生成ca证书,一般与kubernetes共用ca证书,不需要额外生成
mkdir -p ~/TLS/{etcd,k8s}
cd ~/TLS/etcd
cat > /root/TLS/etcd/ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > /root/TLS/etcd/ca-csr.json << EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "Beijing",
"ST": "Beijing",
"O": "k8s",
"OU": "system"
}
]
}
EOF
# 生成ca.pem和ca-key.pem文件
cfssl gencert -initca ca-csr.json |cfssljson -bare ca -
# 生成etcd证书
cat > /root/TLS/etcd/server-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"192.168.124.26",
"192.168.124.27",
"192.168.124.28",
"192.168.124.29",
"192.168.124.30",
"192.168.124.31"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "BeiJing",
"ST": "BeiJing",
"O": "k8s",
"OU": "system"
}
]
}
EOF
# 生成证书文件
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes server-csr.json | cfssljson -bare server
```
## 部署etcd
```bash
ETCD_VER=v3.4.17
DOWNLOAD_URL=https://github.com/etcd-io/etcd/releases/download
mkdir -p /home/etcd/{data,ssl,config,bin}
curl -L ${DOWNLOAD_URL}/${ETCD_VER}/etcd-${ETCD_VER}-linux-amd64.tar.gz -o /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz
tar xzvf /tmp/etcd-${ETCD_VER}-linux-amd64.tar.gz -C /home/etcd/bin --strip-components=1
# 将ca-key.pem、ca.pem、server.pem、server-key.pem放到/home/etcd/ssl下
# 创建etcd配置文件
cat > /home/etcd/config/etcd.yml << EOF
name: 'etcd-01'
data-dir: '/home/etcd/data/default.etcd'
# 本节点与其他节点进行数据交换(选举,数据同步)的监听地址
listen-peer-urls: 'https://1.1.1.1:2380'
# 监听地址,响应客户端请求
listen-client-urls: 'https://1.1.1.1:2379'
# 通知其他节点与本节点进行数据交换(选举,同步)的地址
initial-advertise-peer-urls: 'https://1.1.1.1:2380'
# 用于通知其他ETCD节点,客户端接入本节点的监听地址
advertise-client-urls: 'https://1.1.1.1:2379'
# 如果键空间的任何成员的后端数据库超过了空间配额,etcd发起集群范围的警告,让集群进入维护模式,仅接收键的读取和删除。
quota-backend-bytes: 8589934592
# 历史压缩,保持3小时key的历史记录
auto-compaction-retention: "3"
initial-cluster: 'etcd-01=https://1.1.1.1:2380,etcd-02=https://2.2.2.2:2380,etcd-03=https://3.3.3.3:2380'
# 集群token
initial-cluster-token: 'etcd-demo-cluster'
# 初始集群状态(new/existing),如果此选项设置为existing,etcd将尝试加入现有集群。
initial-cluster-state: 'new'
# 证书相关
client-transport-security:
cert-file: '/home/etcd/ssl/server.pem'
key-file: '/home/etcd/ssl/server-key.pem'
client-cert-auth: true
trusted-ca-file: '/home/etcd/ssl/ca.pem'
peer-transport-security:
cert-file: '/home/etcd/ssl/server.pem'
key-file: '/home/etcd/ssl/server-key.pem'
client-cert-auth: true
trusted-ca-file: '/home/etcd/ssl/ca.pem'
# 日志格式
logger: zap
EOF
# 创建system管理etcd
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
ExecStart=/home/etcd/bin/etcd --config-file=/home/etcd/config/etcd.yml
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# 启动并设置开机启动
systemctl daemon-reload
systemctl start etcd && systemctl status etcd
systemctl enable etcd
```
# etcdctl
```bash
证书相关参数: etcdctl --endpoints=$ENDPOINTS --cert=$certPath --cacert=$cacertPat --key=$keyPath
查看集群信息: etcdctl --endpoints=$ENDPOINTS endpoint status -wtable
查看集群状态: etcdctl --endpoints=$ENDPOINTS endpoint health -wtable
查看成员状态: etcdctl --endpoints=$ENDPOINTS member list -wtable
查看告警信息: etcdctl --endpoints=$ENDPOINTS alarm list
get: etcdctl --endpoints=$ENDPOINTS get /a
etcdctl --endpoints=$ENDPOINTS get /a -wjson
etcdctl --endpoints=$ENDPOINTS get --prefix / --keys-only
etcdctl --endpoints=$ENDPOINTS get /a --rev=0 获取指定revision的值
create: etcdctl --endpoints=$ENDPOINTS put foo "Hello World!"
delete: etcdctl --endpoints=$ENDPOINTS del key
watch: etcdctl --endpoints=$ENDPOINTS watch stock1
etcdctl --endpoints=$ENDPOINTS watch stock --prefix
# 备份
etcdctl --endpoints=$ENDPOINTS snapshot save my.db
etcdctl --endpoints=$ENDPOINTS snapshot status my.db -wtable
# 恢复
etcdctl snapshot restore backup.db \
--name etcd-02 \
--data-dir=/home/etcd/data/default.etcd \
--initial-cluster "etcd-01=https://172.20.101.35:2380,etcd-02=https://172.20.141.201:2380,etcd-03=https://172.20.107.41:2380" \
--initial-cluster-token etcd-demo-cluster \
--initial-advertise-peer-urls https://172.20.141.201:2380
member: etcdctl --endpoints=$ENDPOINTS member remove ${MEMBER_ID}
etcdctl --endpoints=$ENDPOINTS member add ${ETCD_NAME} --peer-urls=http://${ETCD_IP}:2380
# Next, start the new member with --initial-cluster-state existing flag
# 启动新节点时,指定 --initial-cluster-state 为existing
```
# 故障与恢复
## 单台节点故障
1. **将故障节点从集群中踢出**
```bash
1. 获取节点ID
etcdctl --endpoints=$ENDPOINTS --cert=$certPath --cacert=$cacertPat --key=$keyPath member list -wtable
2. 踢出节点
etcdctl --endpoints=$ENDPOINTS --cert=$certPath --cacert=$cacertPat --key=$keyPath member remove $memberID
```
1. **新建节点,添加到集群中**
```bash
1. 新部署etcd节点
2. 添加节点
etcdctl --endpoints=$ENDPOINTS --cert=$certPath --cacert=$cacertPat --key=$keyPath member add ${ETCD_NAME} --peer-urls=http://${ETCD_IP}:2380
3. 修改配置文件 initial-cluster-state 为 existing
初始集群状态(new/existing),如果此选项设置为existing,etcd将尝试加入现有集群。
4. 启动新节点
systemctl start etcd
```
**如果出现以下报错:**
```bash
Jun 23 23:37:09 k8s-nacos-0001.dohko etcd[64335]: {"level":"warn","ts":"2022-06-23T23:37:09.475+0800","caller":"etcdserver/server.go:1095","msg":"server error","error":"the member has been permanently removed from the cluster"}
Jun 23 23:37:09 k8s-nacos-0001.dohko etcd[64335]: {"level":"warn","ts":"2022-06-23T23:37:09.475+0800","caller":"etcdserver/server.go:1096","msg":"data-dir used by this member must be removed"}
```
> 证明该etcd节点还存在旧集群的元数据,无法新加到集群中。 需要将数据目录删除,然后重新启动。
>
## 超过半数节点故障
1. **当前集群以不可用,需要把可用节点先单机运行**
```bash
etcd --name etcd-01 \
--initial-advertise-peer-urls http://192.168.244.13:2380 \
--data-dir /home/etcd/data/default.etcd \
--listen-peer-urls http://192.168.244.13:2380 \
--listen-client-urls http://192.168.244.13:2379,http://127.0.0.1:2379 \
--advertise-client-urls http://192.168.244.13:2379 \
--initial-cluster-token etcd-cluster \
--initial-cluster etcd-01=http://192.168.244.13:2380 \
--initial-cluster-state=new \
--force-new-cluster >> /tmp/etcd.log 2>&1 &
```
> 注意用到了 --force-new-cluster 参数,这个参数会重置集群ID和集群的所有成员信息。以单节点集群启动后,可以正常提供访问了。
>
1. **添加节点到集群**
```bash
1. 将故障节点的原有数据删除
2. 添加节点
etcdctl --endpoints=$ENDPOINTS --cert=$certPath --cacert=$cacertPat --key=$keyPath member add ${ETCD_NAME} --peer-urls=http://${ETCD_IP}:2380
3. 修改配置文件 initial-cluster-state 为 existing
初始集群状态(new/existing),如果此选项设置为existing,etcd将尝试加入现有集群。
4. 启动新节点
systemctl start etcd
```
## 整个集群故障

云原生训练营:etcd
Copyright: 采用 知识共享署名4.0 国际许可协议进行许可

