
# 介绍
- Docker 基于 Linux 内核的 Cgroup,Namespace,以及 Union FS 等技术,对进程进行封装隔离,属于操作系统层面的虚拟化技术,由于隔离的进程独立于宿主和其它的隔离的进程,因此也称其为容器。
- 最初实现是基于 LXC,从 0.7 以后开始去除 LXC,转而使用自行开发的 Libcontainer,从 1.11 开始,则进一步演进为使用 runC 和 Containerd。
# 容器标准
- Open Container Initiative(OCI)
- 轻量级开放式管理组织(项目)
- OCI 主要定义两个规范
- Runtime Specification
- 文件系统包如何解压至硬盘,共运行时运行。
- Image Specification
- 如何通过构建系统打包,生成镜像清单(Manifest)、文件系统序列化文件、镜像配置。
# Namespace
- Linux Namespace 是一种 Linux Kernel 提供的资源隔离方案:
- 系统可以为进程分配不同的 Namespace;
- 并保证不同的 Namespace 资源独立分配、进程彼此隔离,即不同的 Namespace 下的进程互不干扰 。
**Linux Namespace 种类**
- Pid Namespace
- Net Namespace
- Ipc Namespace
- Container 中进程交互还是采用 linux常见的进程间交互方法(interprocess communication - IPC),包括常见的信号量、消息队列和共享内存。
- Container 的进程间交互实际上还是 Host上具有相同 Pid Namespace中的进程间交互,因此需要在 IPC资源申请时加入 Namespace信息,每个 IPC资源有一个唯一的32位ID。
- Mnt Namespace
- 允许不同 Namespace的进程看到的文件结构不同,这样每个Namespace中的进程看到的文件目录就被隔离开了。
- Uts Namespace
- User Namespace
**Namespace常用操作**
```bash
# 查看当前系统的 namespace
lsns -t $Type
# 查看某进程的 namespace
ls -la /proc/<pid>/ns/
# 进入某 namespace 运行命令
nsenter -t $PID -n $Command
# 获取容器的Pid
docker inspect $PID |grep -i pid
# 交互式进入进程的 namespace
nsenter --target $PID --mount --uts --ipc --net --pid
```
# Cgroups
`/sys/fs/cgroup` 中查看cgroup使用情况。
**CPU子系统**
- cpu.shares
- 可出让的能获得 CPU 使用时间的相对值。
- cpu.cfs_period_us
- 用来配置时间周期长度,单位为 us(微秒)。默认为100000
- cpu.cfs_quota_us
- 用来配置当前 Cgroup 在 cfs_period_us 时间内最多能使用的 CPU 时间数,单位为 us(微秒)。默认为100000
`cfs_quota_us /cfs_period_us` 是进程最大可使用的CPU
**CPU子系统练习**
```bash
# demo程序
package main
func main() {
go func() {
for{}
} ()
for{}
}
# 在 cgroup cpu 子系统目录中创建目录结构
cd /sys/fs/cgroup/cpu
mkdir cpudemo
cd cpudemo
# 运行 demo程序,CPU占用200%
# 通过 cgroup限制 cpu
## 把进程添加到cgroup进程配置组
echo $PID > cgroup.procs
## 设置cpuquota
echo 10000 > cpu.cfs_quota_us
# CPU使用率为10%
```
**Memory子系统**
- memory.usage_in_bytes
- cgroup 下进程使用的内存,包含 cgroup 及其子 cgroup 下的进程使用的内存
- memory.max_usage_in_bytes
- cgroup 下进程使用内存的最大值,包含子 cgroup 的内存使用量。
- memory.limit_in_bytes
- 设置 Cgroup 下进程最多能使用的内存。如果设置为 -1,表示对该 cgroup 的内存使用不做限制。
- memory.soft_limit_in_bytes
- 这个限制并不会阻止进程使用超过限额的内存,只是在系统内存足够时,会优先回收超过限额的内存,使之向限定值靠拢。
- memory.oom_control
- 设置是否在 Cgroup 中使用 OOM(Out of Memory)Killer,默认为使用。当属于该 cgroup 的进程使用的内存超过最大的限定值时,会立刻被 OOM Killer 处理。
# 文件系统
**Union FS**
- 将不同目录挂载到同一个虚拟文件系统下 (unite several directories into a single virtual filesystem)的文件系统
- 支持为每一个成员目录(类似Git Branch)设定 readonly、readwrite 和 whiteout-able 权限
- 文件系统分层, 对 readonly 权限的 branch 可以逻辑上进行修改(增量地, 不影响 readonly 部分的)。
- 通常 Union FS 有两个用途, 一方面可以将多个 disk 挂到同一个目录下, 另一个更常用的就是将一个 readonly 的 branch 和一个 writeable 的 branch 联合在一起。
**Docker 的文件系统**
典型的 Linux 文件系统组成:
- Bootfs(boot file system)
- Bootloader - 引导加载 kernel
- Kernel - 当 kernel 被加载到内存中后 umount bootfs
- rootfs (root file system)
- /dev,/proc,/bin,/etc 等标准目录和文件。
Docker 复用 Linux Bootfs,自己实现 rootfs。
**Docker启动**
- 初始化时也是将 rootfs 以 readonly 方式加载并检查,然而接下来利用 union mount 的方式将一个readwrite 文件系统挂载在 readonly 的 rootfs 之上
- 并且允许再次将下层的 FS(file system) 设定为 readonly 并且向上叠加
- 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行时态, 每一个 FS 被称作一个 FS 层
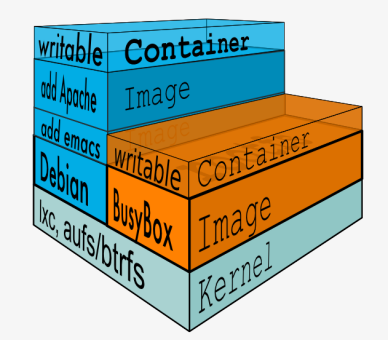
**理解OverlayFS**
Overlay 只有两层:upper 层和 lower 层,Lower 层代表镜像层,upper 层代表容器可写层。
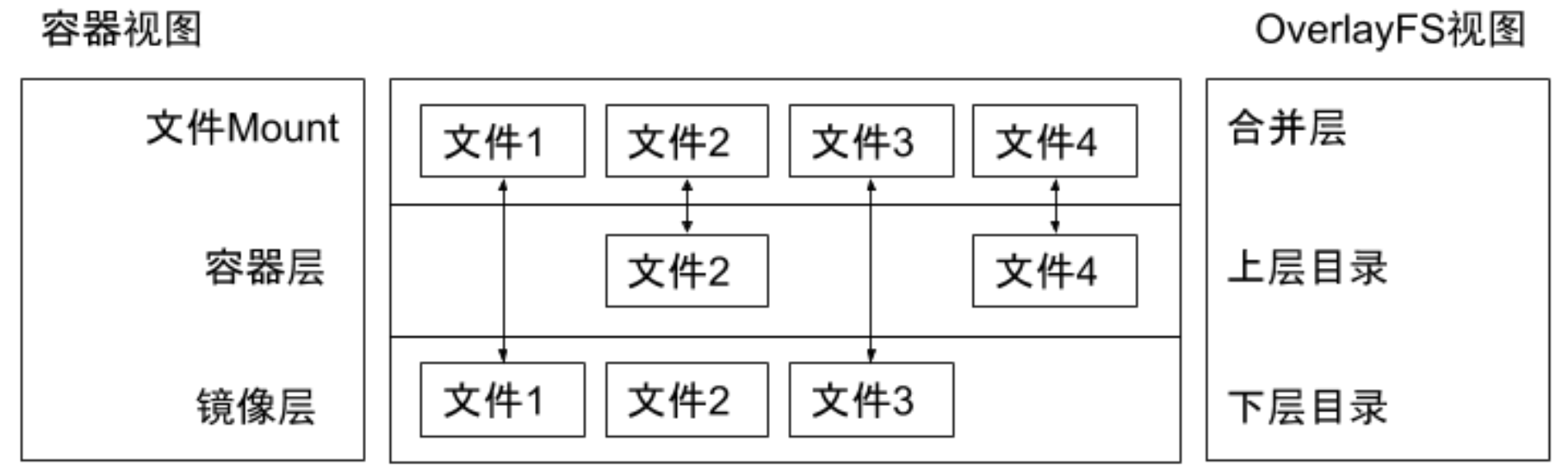
**OverlayFS文件系统练习**
```bash
# 练习一
mkdir upper lower merged work
echo "from lower" > lower/in_lower.txt
echo "from upper" > upper/in_upper.txt
echo "from lower" > lower/in_both.txt
echo "from upper" > upper/in_both.txt
# 将lower、upper合并挂载
sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged
# 练习二
# 创建练习容器
docker run -d nginx
docker inspect $ContainerID
# 查看容器的lower、upper、merge
"GraphDriver": {
"Data": {
"LowerDir": "/var/lib/docker/overlay2/77a18594ec28fa3eeecd1bdcd44f05bec8111ba78eca3be65914933120165aaa-init/diff:/var/lib/docker/overlay2/80bf504e4d808700fa46ed8ca759baa26cb4a81ebe3ff7b9ab5552604013a050/diff",
"MergedDir": "/var/lib/docker/overlay2/77a18594ec28fa3eeecd1bdcd44f05bec8111ba78eca3be65914933120165aaa/merged",
"UpperDir": "/var/lib/docker/overlay2/77a18594ec28fa3eeecd1bdcd44f05bec8111ba78eca3be65914933120165aaa/diff",
"WorkDir": "/var/lib/docker/overlay2/77a18594ec28fa3eeecd1bdcd44f05bec8111ba78eca3be65914933120165aaa/work"
},
"Name": "overlay2"
}
# LowerDir是构建镜像的文件目录,UpperDir是容器运行后写入的文件目录,MergedDir是LowerDir+UpperDir
# df -hT 能看到很多merged的挂载
```
# Docker引擎架构
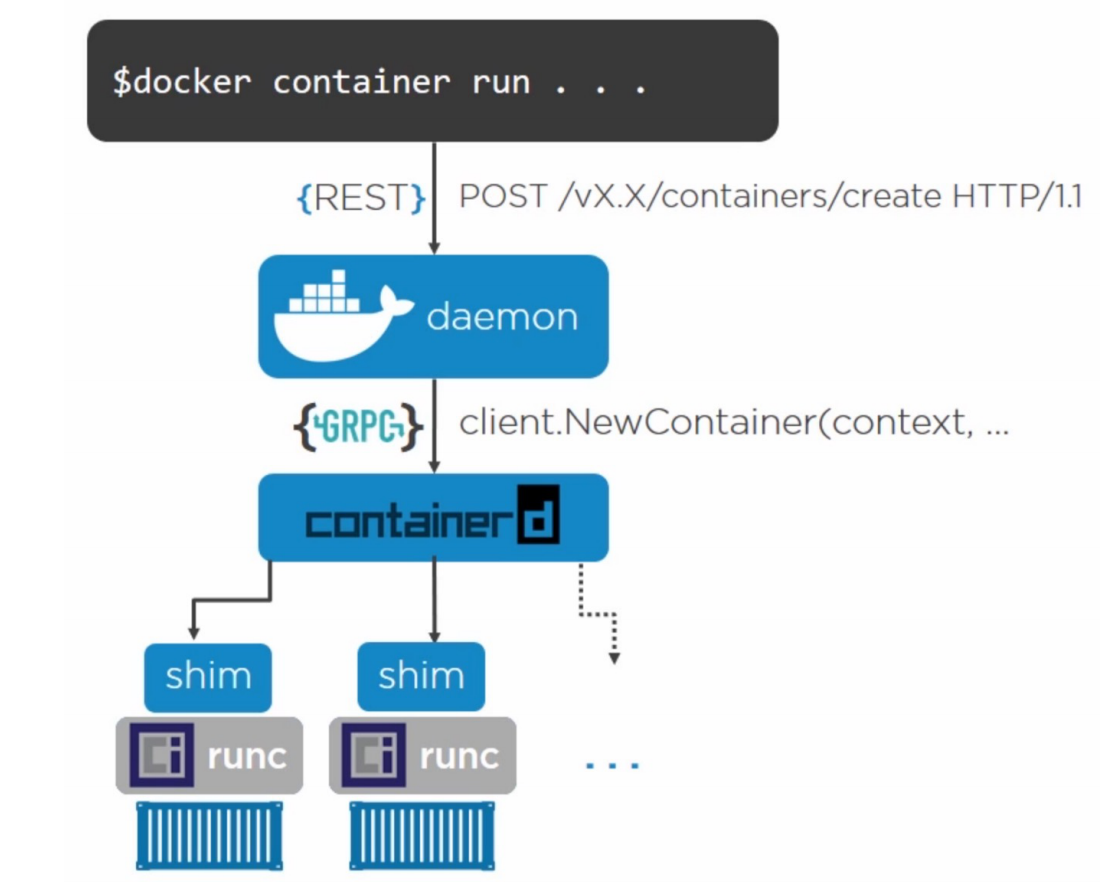
Containerd 是通过创建子进程的方式管理容器,这样有个好处,就是containerd 重启不会影响所有容器。如下:
```bash
[root@zzzzz go]# docker inspect bb833c7f0ca2|grep -i pid
"Pid": 1936784,
"PidMode": "",
"PidsLimit": null,
[root@zzzzz go]# ps -ef |grep 1936784
root 1936784 1936766 0 01:26 ? 00:00:00 nginx: master process nginx -g daemon off;
101 1936838 1936784 0 01:26 ? 00:00:00 nginx: worker process
101 1936839 1936784 0 01:26 ? 00:00:00 nginx: worker process
[root@zzzzz go]# ps -ef |grep 1936766
root 1936766 7452 0 01:26 ? 00:00:00 containerd-shim -namespace moby -workdir /var/lib/containerd/io.containerd.runtime.v1.linux/moby/bb833c7f0ca2551f5fdfbda4ace233c950ba4d27e88acf9f5d4c04c1f852f4e9 -address /run/containerd/containerd.sock -containerd-binary /usr/bin/containerd -runtime-root /var/run/docker/runtime-runc
[root@zzzzz go]# ps -ef |grep 7452
root 7452 1 0 Mar04 ? 00:33:36 /usr/bin/containerd
```
云原生训练营:Docker核心技术
Copyright: 采用 知识共享署名4.0 国际许可协议进行许可
Links: https://blog.zs-fighting.cn/archives/云原生训练营docker核心技术

